Khi
trí tuệ nhân tạo (AI) ngày càng được ứng dụng rộng rãi, thậm chí đã “xâm chiếm”
các tòa soạn như kết luận của Hiệp hội Báo chí quốc tế INMA, câu hỏi không còn
là có nên dùng AI hay không, mà là làm thế nào để AI thực sự tạo ra giá trị.
“Nhiên liệu” vận hành hệ thống AI
Trong
hành trình hai năm qua, ngành báo chí thế giới đã chuyển dịch mạnh mẽ từ sự tò
mò ban đầu về công nghệ sang việc triển khai thực tiễn các giải pháp AI. Tuy
nhiên, đằng sau sự hào nhoáng của các mô hình ngôn ngữ lớn (LLM) là một thực tế
cốt lõi: AI chỉ có thể mạnh mẽ khi có dữ liệu đủ tốt. Dữ liệu không còn là những
con số thống kê khô khan mà đã trở thành mạch máu, là nền tảng để các nhà xuất
bản tái định nghĩa cách làm tin tức, tương tác với độc giả và tìm kiếm mô hình
doanh thu bền vững.
Một
trong những bước tiến đột phá nhất mà dữ liệu mang lại chính là khả năng
"siêu cường hóa" năng lực báo cáo và điều tra. Thay vì chỉ dựa vào
các nguồn tin con người, các tòa soạn hiện đại đang sử dụng AI để xử lý các kho
dữ liệu khổng lồ mà trước đây con người không thể thực hiện thủ công. Chẳng hạn,
tờ New York Times đã huấn luyện công cụ AI để nhận diện các hố bom từ loại bom
2.000 pound trên ảnh vệ tinh, từ đó xác nhận việc quân đội Israel ném bom vào các vùng an toàn của
dân thường tại Gaza.
đội Israel ném bom vào các vùng an toàn của
dân thường tại Gaza.
Hãng
tin AP thì xử lý hơn 200.000 trang tài liệu và hàng trăm giờ video camera hành
trình của cảnh sát để vạch trần các hành vi bạo lực có hệ thống của cơ quan thực
thi pháp luật tại Mỹ. Tờ The Wall Street Journal đã biến hơn 41.000 bài đăng
trên mạng xã hội của Elon Musk thành các "vector" dữ liệu để lập bản
đồ sự thay đổi trong quan điểm chính trị của tỷ phú này.
Ví
dụ khác về việc phát triển bạn đọc, khi lưu lượng truy cập từ các nền tảng bên
thứ ba (như Search và Social) đang cạn kiệt, các tòa soạn buộc phải quay lại
xây dựng mối quan hệ trực tiếp với độc giả. Ở đây, dữ liệu chính chủ
(first-party data) đóng vai trò là "chìa khóa vàng". Theo báo cáo của
INMA, 67% các nhà xuất bản tin tức hiện đang sử dụng AI để phân phối nội dung dựa
trên dữ liệu người dùng.
Dữ
liệu cũng giúp các tổng biên tập đưa ra các quyết định dựa trên bằng chứng thay
vì chỉ dựa vào cảm tính. Tờ Iltalehti (Phần Lan) đã phát triển các bảng điều
khiển theo dõi cảm xúc của độc giả đối với từng bài viết. Dữ liệu cho thấy các
bài viết mang tính xây dựng có tỷ lệ chuyển đổi thuê bao (tức trả phí để đăng
ký đọc báo online) cao nhất, giúp phóng viên điều chỉnh văn phong để giảm bớt sự
"mệt mỏi tin tức" của công chúng.

Rõ
ràng, AI đang tái định hình mọi ngóc ngách của các tòa soạn, từ quy trình sản
xuất, phân phối tin tức cho đến chiến lược thương mại. Nhưng chỉ có điều, không
phải tòa soạn nào cũng thành công, và thành bại nằm ở yếu tố dữ liệu như INMA
đã khẳng định ở đầu bài.
Đồng
tình với quan điểm này, ông Trương Trí Vĩnh, nguyên Thư ký tòa soạn Forbes Việt
Nam cho hay, chiến lược ứng dụng AI của nhiều tòa soạn thất bại không phải do
thiếu công nghệ, mà vì AI đang được triển khai trên một cấu trúc tổ chức chưa
được dữ liệu hóa đầy đủ. Không ít quy trình quan trọng trong hoạt động báo chí
vẫn dựa vào kinh nghiệm cá nhân, biên tập viên quyết định theo cảm tính, việc gắn
nhãn chưa được chuẩn hóa; và tri thức nằm rải rác trong từng ban, từng cá nhân
thay vì được chuyển hóa thành hệ thống dữ liệu. Trong bối cảnh đó, AI không có
đủ ngữ cảnh cần thiết để học và phát huy hiệu quả.
Ông
Vĩnh cũng phân tích điểm khác biệt căn bản giữa một tòa soạn truyền thống và một
tòa soạn vận hành theo hướng dữ liệu. Theo đó, một hạ tầng dữ liệu tốt giúp các
tuyến nội dung được chuẩn hóa thành sản phẩm, vận hành như một dòng sản phẩm có
dữ liệu, vòng đời rõ ràng, hiểu biết về bạn đọc và khả năng phản ứng theo thời
gian thực. Khi đó, một chủ đề không chỉ dừng lại ở một bài báo đơn lẻ, mà có thể
được phát triển thành nhiều định dạng khác nhau như tin nhanh, video ngắn,
infographic, livestream, bài giải thích, newsletter hay social clip, tùy theo
hành vi tiếp nhận của công chúng trên từng nền tảng. Thậm chí, một chủ đề có thể
được triển khai thành nhiều “mùa nội dung” (season) khác nhau.

Nhờ
vậy, bạn đọc có thể tiếp cận cùng một chủ đề dưới nhiều hình thức đa dạng, trên
nhiều kênh phân phối khác nhau. Điều này phù hợp với thuật ngữ “liquid content”
(nội dung lỏng, hoặc nội dung linh hoạt) được nhiều chuyên gia báo chí trên thế
giới nhắc tới nhiều trong thời gian gần đây, thậm chí được INMA coi là thuật ngữ
phổ biến nhất của báo chí trong năm 2026.
Nhấn
mạnh vai trò thiết yếu của hạ tầng dữ liệu trong một cơ quan báo chí, ông Bùi
Công Duyến - Giám đốc sản phẩm Tòa soạn hội tụ ONECMS, Công ty cổ phần Công nghệ
NEKO, khẳng định, khi một tòa soạn có dữ liệu sạch, có đầy đủ thông tin đi kèm,
AI sẽ hỗ trợ rất hiệu quả cho phóng viên và biên tập viên: từ gợi ý tư liệu
(hình ảnh, âm thanh, video, số liệu...), tóm tắt hồ sơ, hỗ trợ tìm kiếm thông
tin liên quan, đến phát hiện nội dung trùng lặp hay hỗ trợ đa nền tảng. Ngược lại,
nếu dữ liệu bị phân mảnh và thiếu thông tin, AI càng mạnh thì rủi ro càng lớn.
“Hiện
nay, ở hầu hết các tòa soạn, khi phóng viên xử lý ảnh cho bài viết, họ thường
chỉ tải ảnh lên hệ thống CMS mà không kèm theo các thông tin mô tả như địa điểm
chụp, sự kiện liên quan hay những nhân vật xuất hiện trong ảnh. Khi dữ liệu thiếu
các yếu tố ngữ cảnh này, AI gần như không thể hiểu đầy đủ nội dung để hỗ trợ hiệu
quả cho quá trình tác nghiệp”, ông Bùi Công Duyến phân tích
"Khi dữ liệu thiếu các yếu tố ngữ cảnh, AI gần như không thể hiểu đầy
đủ nội dung để hỗ trợ hiệu quả cho quá trình tác nghiệp”.
- Ông Bùi Công Duyến
Qua kinh nghiệm
triển khai thực tế tại tòa soạn, Phó Tổng Biên tập VnExpress Nguyễn Thu Hương
cũng cho rằng: "AI không thể tự thông minh nếu chúng ta chỉ 'ném' cho nó một
kho văn bản khổng lồ. Việc chuyển hóa dữ liệu phi cấu trúc (văn bản tự do, hình
ảnh thô...) thành dữ liệu có cấu trúc thông qua hệ thống metadata (siêu dữ liệu) chuẩn
chỉnh là bước đi quyết định để AI đưa ra các gợi ý chính xác, thay vì chỉ phân
phối bài viết dựa trên các từ khóa bề nổi".
Những điểm nghẽn cần tháo gỡ
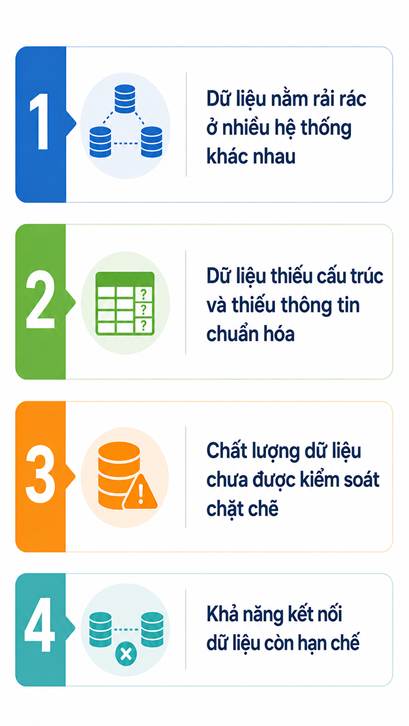
Từ
kinh nghiệm hợp tác với nhiều tòa soạn hội tụ tại Việt Nam, ông Bùi Công Duyến
đã chỉ ra bốn điểm nghẽn lớn nhất về hạ tầng dữ liệu trong môi trường báo chí
hiện nay.
Trước
hết, dữ liệu vẫn nằm rải rác ở nhiều hệ thống khác nhau: tin bài, hình ảnh,
video lưu trong một CMS cũ; ảnh được lưu ở kho riêng; video nằm trên nền tảng
khác; nhiều tư liệu quan trọng lại được cất trong email hoặc trên thiết bị cá
nhân của phóng viên. Thậm chí, không ít tòa soạn vẫn duyệt bài báo in qua thư
điện tử hoặc các ứng dụng nhắn tin, gọi điện.

Điểm
nghẽn thứ hai là dữ liệu thiếu cấu trúc và thiếu thông tin chuẩn hóa. Nhiều kho
dữ liệu báo chí tích lũy trong nhiều năm chỉ tồn tại dưới dạng văn bản thô,
không được gắn thẻ về chủ đề, nhân vật, địa danh hay các thông tin nhạy cảm cần
kiểm soát.
Điểm
nghẽn thứ ba là chất lượng dữ liệu chưa được kiểm soát chặt chẽ. Nhiều dữ liệu
đã cũ nhưng chưa được cập nhật; thông tin sai chưa được đính chính; thậm chí có
những nội dung chưa kiểm chứng lại được xếp chung với dữ liệu chính thức. Nếu
AI học từ những nguồn dữ liệu này, các sai sót sẽ bị khuếch đại với tốc độ rất
nhanh. Trong lĩnh vực báo chí, dữ liệu sai nhưng được AI trình bày một cách
thuyết phục còn nguy hiểm hơn cả việc thiếu dữ liệu.
Điểm
nghẽn tiếp theo là thiếu khả năng kết nối dữ liệu. Nhiều hệ thống hiện nay vẫn
hoạt động như những “ốc đảo”, chưa có cơ chế kết nối mở để AI có thể truy xuất
dữ liệu theo thời gian thực một cách an toàn và có kiểm soát. Ngoài ra còn một
vấn đề rất quan trọng nhưng thường bị xem nhẹ, đó là quản trị dữ liệu và bản
quyền.
Dựa
trên kinh nghiệm triển khai thực tế, ông Bùi Công Duyến cho rằng, một hạ tầng dữ
liệu sẵn sàng cho AI trong tòa soạn cần đáp ứng các tiêu chí nền tảng, trong đó
điều quan trọng là dữ liệu cần được hợp nhất.
Tin
bài, hình ảnh, video, hồ sơ đề tài và dữ liệu tác nghiệp cần được tập trung hoặc
ít nhất phải có khả năng truy xuất đầy đủ từ các hệ thống khác nhau. Nếu mỗi bộ
phận duy trì một kho dữ liệu riêng, AI sẽ khó phát huy hiệu quả.
“Đây
cũng chính là triết lý của mô hình tòa soạn hội tụ mà chúng tôi theo đuổi lâu
nay: Hội tụ không chỉ ở quy trình làm báo mà trước hết phải ở dữ liệu”, ông Bùi
Công Duyến phân tích.
Theo
khảo sát của Hội Nhà báo Việt Nam, hiện không có nhiều tòa soạn đáp ứng được đầy
đủ các tiêu chí đó. Dù tiềm năng là rất lớn, nhưng báo cáo của INMA cũng chỉ rõ
những rào cản khiến nhiều sáng kiến dữ liệu thất bại. Thành công của AI đòi hỏi
các tòa soạn phải coi cơ sở hạ tầng dữ liệu là ưu tiên hàng đầu.
Trong
khi đó, từ góc độ của một chuyên gia phát triển dự án về xử lý dữ liệu, theo
ông Trương Trí Vĩnh, để AI có thể vận hành hiệu quả ở quy mô tòa soạn thay vì ở
phạm vi cá nhân đơn lẻ, hạ tầng dữ liệu cần có ít nhất bốn lớp: 1. Dữ liệu nội
dung: Các nội dung được tích luỹ và phân theo nhiều chiều; 2. Dữ liệu bạn đọc:
Tập trung vào hành vi tiếp nhận thông tin của bạn đọc; 3. Dữ liệu nghiệp vụ:
Đây là lớp hay bị bỏ quên, nhưng nó quyết định cách thức vận hành tòa soạn dựa
trên AI; 4. Quản trị và AI.
“Tương
lai của AI trong lĩnh vực báo chí không phải là thay nhà báo bằng các chatbot,
mà là xây dựng một tòa soạn có khả năng tự học từ dữ liệu vận hành của chính
mình”, ông Trương Trí Vĩnh khẳng định.
Và
do đó, ngành báo chí cũng sẽ chứng kiến sự dịch chuyển kỹ năng, làm thay đổi
tiêu chuẩn tuyển dụng. Đơn cử, tờ báo lớn nhất Ấn Độ Times of India cho biết họ
không còn ưu tiên quá mức kỹ năng ngôn ngữ thuần túy mà chú trọng vào những người
có khả năng báo cáo mạnh mẽ và biết cách tương tác với các công cụ dữ liệu.
“Chúng
ta đang tiến tới kỷ nguyên của Tác nhân AI (Agentic AI) - nơi các hệ thống có bộ
nhớ bền vững, khả năng học hỏi lặp đi lặp lại và hiểu sâu sắc nhu cầu của từng
độc giả”, INMA kết luận trong báo cáo được phát đi cuối năm 2025.
Nhưng
báo cáo này cũng bỏ ngỏ: Dù dữ liệu và AI có mạnh mẽ đến đâu, báo chí vẫn cần sự
nhạy bén và đạo đức của con người. Sự chính trực của báo chí không phải là một
tính năng của các mô hình ngôn ngữ lớn. Dữ liệu là công cụ giúp các tòa soạn
nhanh hơn, thông minh hơn, nhưng chính những kết nối thực thụ giữa người với
người mới là giá trị khác biệt khiến độc giả sẵn lòng chi trả trong kỷ nguyên số.
Nguồn bài viết: Báo Nhân dân